The "Color Face" made of newspapers, source image from pixabay.com/photos/girl-face-colorful-colors-artistic-2696947 . Credit: Dai et al.
Researchers at Seoul National University have recently tried to train an artificial intelligence (AI) agent to create collages (i.e., artworks created by sticking various pieces of materials together), reproducing renowned artworks and other images. Their proposed model was introduced in a paper pre-printed on arXiv and presented at ICCV 2023 in October.
"Collage art requires high human artistry, and we wondered what collage artworks created by AI would look like," the authors told Tech Xplore by email, "Existing AI image generation tools like DALL-E or StableDiffusion can already generate collage images, but they are just 'collage-imitations' from pixels, not the actual collage from carrying out the real steps of collage artwork, What we wanted to do was to train AI to create 'real collage'."
In a previous study focusing on painting generation, researchers used reinforcement learning (RL) to teach AI to paint following steps similar to those followed by humans. They then started wondering if this could also be achieved for the creation of collages and started working on their reinforcement learning-based autonomous collage artwork generator.
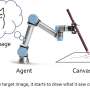
The primary objective of their recent paper was thus to train an AI agent to create collages that are as similar to target images (e.g., paintings, photographs, etc.) as possible by tearing and pasting multiple materials, using reinforcement learning. These collages would be created using a set of materials provided by human users.
"Our RL model needs to make an agent understand what a collage is and how to do it well," the authors explained. "As RL basically requires many trials and errors, the model needs to gain experience interacting with a canvas and producing an actual collage."
As collages are made of various scraps of materials, to effectively create these artworks, an agent first needs to test diverse cut-and-paste options to ultimately determine which materials produce a collage that best resembles target images. The researchers found that initially, their model performed very poorly, yet over time, its skills significantly improved.
"The RL agent learns to make the reward bigger, where the reward is defined as an improvement in the similarity between their canvas and a target image," the authors said. "The reward function also keeps evolving over time, learning to better evaluate the similarity between agent-made collage and the target image."
During training, the researchers' model was fed a randomly assigned random image and tried to create a collage reproducing this image on a white canvas. At every step of the collage, the agent selects a random material among available options and chooses how to cut it, scrap it, and paste it onto the canvas.
"Because the target images and materials are randomly given in training, the agent becomes able to deal with any targets and materials at a later stage," the authors said. "This whole process is a bit complicated for using existing model-free RL, so we developed a differentiable collaging environment to allow the agent to track the collage's dynamics easily. This allowed us to apply model-based RL and enhance performance."
The model-based RL training scheme developed by the researchers draws inspiration from the previous work about RL-based paintings. However, the team developed their own model-based RL algorithm that addressed the dynamics associated with creating collages, which are more complex than those underpinning painting.
The "Bird" made of newspapers, target image from pixabay.com/photos/kingfisher-bird-close-up-perched-2046453 . Credit: Dai et al.
"While painting uses a predefined brushstroke, a collage needs to observe how the given material looks and figure out how to manipulate it to make a proper image fragment for the total collage, comprehending shape, texture, colors, and coordinates," the authors said. "Since SAC allows an agent to experience diverse actions more effectively in the continuous action space than DDPG, which was used in paintings, SAC matches our case."
To effectively generate collages, the authors used their trained model as a partial collage generator unit. This unit was found to produce high-resolution collages which closely resembled various target images.
"We also developed a module for analyzing target image complexity to assign more workload for partial collage generator to the place where the complexity is high," Lee explained. "This module can enhance the aesthetic quality of collages."
A crucial advantage of the team's architecture is that it does not require any collage samples and demonstration data, as it was simply trained using examples of materials and target images. Notably, these materials and images are far easier to collect than original artworks.
"Without artistic data or knowledge, the agent independently learned how to make a collage," the authors said. "The final collaging ability was made by the agent's own exploration, which is the notable finding of this work; it shows the mighty ability of RL as a data-free learning domain."
The "Church" made of newspapers. Credit: Dai et al.
As the team's trained model gradually grasped the process of collage-making, it could generalize well across a wide range of images and scenarios. So far, it has only been tested in simulations. However, if applied to a humanoid robot or a robotic hand, the model could also provide 'blueprints' for the creation of physical collages.
"Building an environment in which the RL agent can learn properly was very challenging," the authors said. "We spent a lot of time developing and defining collage dynamics and actions that are legit for RL. Also, to save training time, we should keep them as compact and efficient as possible. Even more, we had to keep the dynamics differentiable for our model-based RL scheme as well."
As art is highly subjective, evaluating the quality of collages produced by the model is challenging. The researchers initially carried out a user study, asking various human participants to share their opinions and feedback on the AI-created collages.
"We conducted a user study, but this may not be enough," the authors said. "After much consideration for more objective evaluation, we decided to use CLIP, a large vision-language pre-trained model. Because CLIP is trained with about 400M text-image pairs, we believe it has the ability to evaluate more objectively than user study. With user study and CLIP, we compared our model with other pixel-based generation models by evaluating generated images' collage-ness and content consistency."
The user study and the CLIP-based evaluation carried out by the researchers yielded similar results. In both these tests, the new model was found to outperform other models for collage generation.
The "Girl with a Pearl Earring" made of newspapers. Credit: Dai et al.
The model introduced in this recent paper could soon be developed further and tested to allow customized styles using a broader range of images and materials. In addition, the team's work could inspire the development of additional AI tools for generating various types of artwork.
"We are now interested in developing strategies that allow our models to cope with various style preferences," the authors added said. "As a future work, we consider developing a user-interactive interface, which can reflect user's preference during our model's creating collages."
More information: Ganghun Lee et al, Neural Collage Transfer: Artistic Reconstruction via Material Manipulation, arXiv (2023). DOI: 10.48550/arxiv.2311.02202
Ganghun Lee et al, From Scratch to Sketch: Deep Decoupled Hierarchical Reinforcement Learning for Robotic Sketching Agent, 2022 International Conference on Robotics and Automation (ICRA) (2022). DOI: 10.1109/ICRA46639.2022.9811858
Journal information: arXiv
© 2023 Science X Network